Update (23 July 2018): The python package kero is up and ready! Here is the code in github.
Hiyah! We know this is the age for data science, IoT, blockchains and there are more interesting stuffs happening. As much as I want, I cannot follow all of them at once, so, I shall settle down with data, data and more data! For this post, I would like to demonstrate the usage of a package I wrote called DataHandler in my github. We will still use PyCharm, python 3.5.1.
The final objective is of course to process data: given probably very large volume of data, we train a model and make it predict the outcome of a new set of data. For example, later on I will post the usage of Convolutional Neural Network (CNN) on the Loan Problem. In the example, we have the data of a number of applicants and their eligibility status. For an applicant, either he is eligible or not, based on, say, their income etc. We make a CNN model, and then train it with this set of data, usually named “train.csv”. Then we will be given “test.csv”, which is the same as “train.csv” except that we do not know whether the applicant is eligible for the loan or not. We want our CNN model to tell us whether the applicants in “test.csv” are eligible.
The problem is, our “train.csv” is not always clean. It comes with all sorts of problems, for example misspelling or missing data. We will have to do some patch work and fill-in-the-blanks. We may never know what are the missing data, but we can reasonably guess, or we may even take the average of the rest of the data and fill the blank with it, just so that our model will not stumble upon empty data and get stuck.
This pre-processing series talks about the DataHandler package that is capable of doing this patch work.
Initiate Random Tables
We want to simulate having data of various shapes and sizes. This package provides a way to initiate systematically and randomly data tables that can take in different data type, such as integer, strings, doubles etc.
Create an empty python project using PyCharm, name it say, myrandtable. Copy every file from folder v0.2 downloaded or cloned from this github repository into it. In this project, create file createtable.py with the following code.
import kero.DataHandler.RandomDataFrame as RDF
import numpy as np
rdf=RDF.RandomDataFrame()
col1={"column_name": "first", "items":[1,2,3]}
itemlist=list(np.linspace(10,20,8))
col2={"column_name": "second", "items": itemlist}
df,_=rdf.initiate_random_table(4,col1,col2,panda=True)
print(df)
Output like this will be printed, with 2 columns, namely “first” and “second”.
first second 0 1 17.142857 1 3 12.857143 2 1 17.142857 3 2 10.000000
We have created our random table! See the documentation here, or in the user manual from the repository.
Puncture a table
Now we simulate having a data that has some defects, such as blanks. In the same project, create new file createbadtable.py with the following code.
import numpy as np
import kero.DataHandler.RandomDataFrame as RDF
rdf = RDF.RandomDataFrame()
output_label = "classification"
csv_name = "check_table_defect_index.csv"
rate = 0.01
with_unique_ID = True
col1 = {"column_name": "first", "items": [1, 2, 3]}
itemlist = list(np.linspace(10, 20, 48))
col2 = {"column_name": "second", "items": itemlist}
col3 = {"column_name": "third", "items": ["gg", "not"]}
col4 = {"column_name": "fourth", "items": ["my", "sg", "id", "jp", "us", "bf"]}
if output_label is not None:
if output_label=="classification":
col_out={"column_name": "result", "items": ["classA","classB","classC"]}
rdf.initiate_random_table(20, col1, col2, col3, col4,col_out, panda=True)
else:
rdf.initiate_random_table(20, col1, col2, col3, col4, panda=True,with_unique_ID=with_unique_ID)
# up to here we are creating a dataframe
# now we puncture all columns of the dataframe.
rdf.crepify_table(rdf.clean_df, rate=rate)
try:
rdf.crepified_df.to_csv(csv_name, index=False)
except:
print("check_initiate_random_table. Error.")
The code yields the following check_table_defect_index.csv file that looks like the following. The documentation is here.
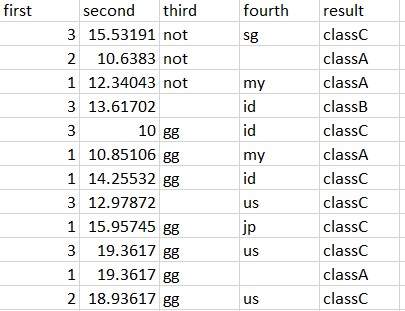
Now we are good! We can tinker with this sort of “realistic” data, manipulate them, patch them etc to the format suitable for processing by machine learning methods like Convolutional Neural Network. We shall see in the next part other pre-processing methods.
